来源:小编 更新:2025-10-25 02:53:17
用手机看
你有没有想过,大数据时代,Hadoop生态系统里的工具就像是魔法师手中的魔杖,能帮你轻松驾驭海量数据呢?今天,就让我带你一起探索这些神奇的宝贝吧!
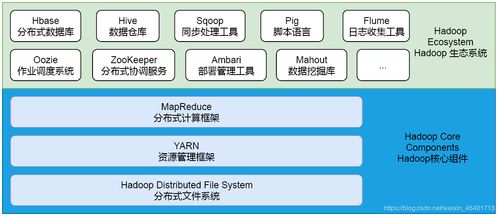
想象你面前堆满了成山成堆的数据,这些数据就像是无头苍蝇一样,让你无从下手。别担心,Hadoop生态系统里的工具就是你的救星!它们能帮你整理、分析、处理这些数据,让你从数据中找到宝藏。
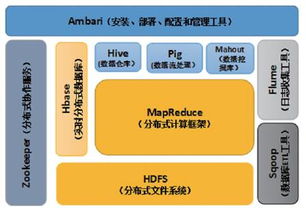
首先,我们要介绍的是Hadoop分布式文件系统(HDFS)。它就像是一个巨大的仓库,能存储海量数据。HDFS将数据分割成小块,分布存储在多个节点上,这样即使某个节点出现问题,也不会影响到整个系统的运行。
HDFS的特点是高可靠性、高吞吐量和高扩展性。它支持的数据格式包括文本、图片、视频等,是Hadoop生态系统的基础。
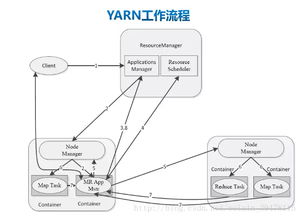
接下来,我们要说的是Hadoop YARN。YARN是Hadoop的资源管理器,它负责分配和管理集群中的资源。简单来说,YARN就像是一个调度员,确保每个任务都能得到足够的资源。
YARN的出现使得Hadoop生态系统更加灵活,可以支持更多的计算框架,如Spark、Flink等。它让Hadoop不再局限于处理大数据,还能处理实时数据。
Apache Hive是Hadoop生态系统中的数据仓库工具。它允许你使用类似SQL的查询语言来处理和分析数据。Hive就像是一个翻译官,将你的查询翻译成Hadoop可以理解的语言。
Hive非常适合处理结构化数据,它支持多种数据格式,如HDFS、HBase等。此外,Hive还提供了丰富的数据操作功能,如数据导入、导出、数据转换等。
Apache HBase是一个分布式、可扩展的NoSQL数据库。它建立在HDFS之上,提供了类似于传统数据库的随机、实时读写能力。HBase就像是一个快速通道,让你能够快速访问数据。
HBase适用于存储非结构化或半结构化数据,如日志、传感器数据等。它支持多种数据模型,如列式存储、行式存储等,可以根据实际需求进行选择。
Apache Spark是Hadoop生态系统中的明星工具之一。它是一个快速、通用的大数据处理引擎,支持多种编程语言,如Java、Scala、Python等。Spark就像是一个多面手,既能处理批处理任务,也能处理实时数据。
Spark的核心优势在于其高效的内存计算能力。它可以将数据加载到内存中,进行快速处理,从而大大提高数据处理速度。此外,Spark还支持多种数据源,如HDFS、HBase、Cassandra等。
Hadoop生态系统中的工具就像是你的数据魔法师,能帮助你轻松驾驭海量数据。无论是HDFS、YARN、Hive、HBase还是Spark,它们都能在不同的场景下发挥出巨大的作用。所以,赶快掌握这些工具,让你的数据之旅更加精彩吧!

















